1. Recap
From its introduction in 2011, the C++ concurrency model has faced a great deal of scrutiny, leading to various refinements of the standard, and a list of fixes to known issues that are yet to be incorporated. P0668R5: Revising the C++ Memory Model describes changes needed to incorporate the fixes of RC11, the latest revision of the existing C++ concurrency design, solving most known problems.
This process of scrutiny and refinement has produced a mature model, but it has also uncovered major problems. The out-of-thin-air problem, discussed most recently in P1217R1: Out-of-thin-air, revisited, again does not yet have a convenient solution: existing solutions -- like the Promising Semantics -- discard the mature concurrency model of the standard and start afresh with a different paradigm. Implementing such a change would require a wide-ranging rewrite of the standard.
The out-of-thin-air problem arises from an under-specification of which program dependencies ought to order memory accesses. The trouble is neatly explained by example.
// Thread 1 r1 = x . load ( memory_order :: relaxed ); y . store ( 1 , memory_order :: relaxed ); // Thread 2 r2 = y . load ( memory_order :: relaxed ); x . store ( 1 , memory_order :: relaxed );
In the example above, called Load Buffering (LB), C++ allows the execution where
// Thread 1 r1 = x . load ( memory_order :: relaxed ); y . store ( r1 , memory_order :: relaxed ); // Thread 2 r2 = y . load ( memory_order :: relaxed ); x . store ( r1 , memory_order :: relaxed );
In the example above, taken from P1217R1, there are now data dependencies from load to store and no explicit write of any value. Surprisingly, the outcome 42 is allowed by the C++ standard -- we say that the value 42 is conjured from thin-air.
// Thread 1 r1 = x . load ( memory_order :: relaxed ); if ( r1 == 42 ) { y . store ( 42 , memory_order :: relaxed ); } // Thread 2 r2 = y . load ( memory_order :: relaxed ); if ( r2 == 42 ) { x . store ( 42 , memory_order :: relaxed ); }
A similar behaviour can be exhibited using control dependencies, as above. The thin-air outcomes of LB+datas and LB+ctrls are the result of a design choice that aims to permit compiler optimisation: some optimisations remove syntactic dependencies, so if C++ bestows ordering to no dependencies, the compiler is free to remove what it likes.
// Thread 1 r1 = x . load ( memory_order :: relaxed ); if ( r1 == 42 ) { y . store ( 42 , memory_order :: relaxed ); } else { y . store ( 42 , memory_order :: relaxed ); } // Thread 2 r2 = y . load ( memory_order :: relaxed ); if ( r2 == 42 ) { x . store ( 42 , memory_order :: relaxed ); }
In Thread 1 above, a compiler may spot that, whatever value is read, the write will be made regardless, optimising to the program below, and allowing both threads to read 42:
// Thread 1 r1 = x . load ( memory_order :: relaxed ); y . store ( 42 , memory_order :: relaxed );
As it stands, the standard allows both threads to read 42 and hence it permits the optimisation, but it also allows the thin-air outcomes in LB+datas and LB+ctrls. P1217R1 explains that these outcomes cannot occur in practice and must be forbidden to enable reasoning and formal verification.
2. Our Solution
P0422R0: Out-of-Thin-Air Execution is Vacuous highlights a series of litmus tests, borrowed from Java, that constrain the ideal behaviour of an improved semantics (e.g. JCTC4, JCTC13 and JCTC6 above). The paper makes the observation that the thin-air execution of each test features a cycle in ( ∪ ) where , semantic dependency, is an as yet undefined relation that captures only the real dependencies that the compiler will leave in place. If only we forbid cycles in ( ∪ ), then the model would have the behaviour we desire.
P1217R1 highlights a simple way to guarantee a lack of thin-air behaviour: forbid the reordering of relaxed loads with following stores. This is equivalent to forbidding cycles in ( ∪ ), and is sufficient to avoid cycles in ( ∪ ). This approach is controversial because it may have a substantial overhead, especially on GPUs.
Our solution is to provide a definition of , and to forbid cycles in ( ∪ ). We have a (sketch) proof that our solution does not incur any overhead at all; that it supports the optimum compilation strategies for Power, ARM, X86 and RISC-V; and that a DRF-SC result holds.
The standard describes the three stages of working out the concurrent behaviour of a program:
-
Generate a list of pre-executions from the source of a program, each corresponding to an arbitrary choice of read values.
-
Pair each pre-execution with reads-from and modification order relations that capture the dynamic memory behaviour of the program, and filter, keeping those that are consistent with the rules of the memory model.
-
Finally, check for races: race free programs have the consistent executions calculated in step 2, racy programs have undefined behaviour.
We augment this scheme by calculating in step 1.
3. Modular Relaxed Dependency
This section explains the idea behind MRD by example, referring back to the programs already discussed.
First we discuss LB+datas. C++ allows the program to read 42, despite there being no write of 42. It is the clearest example of thin-air behaviour and it should be forbidden.
r1 = x . load ( memory_order :: relaxed ); y . store ( r1 , memory_order :: relaxed );
Above is the first thread of LB+datas. We will contrast the pre-execution that is constructed in the existing C++ definition with the structure built by MRD.
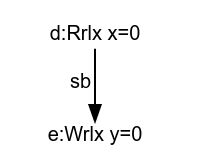
| 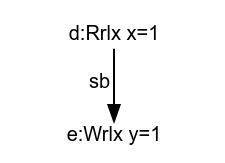
| 
|
|---|---|---|
| C++ Pre-executions | MRD Event Structure | |
On the left above is a list of pre-executions of this first thread -- note that we restrict the value set here to 0 and 1 to keep the diagrams tractable, so this list covers all of them. The C++ model intentionally ignores dependencies, so the events of each pre-execution are ordered only by sequenced before.
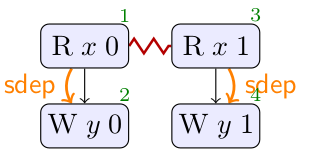
On the right is the structure generated by MRD (an event structure in the jargon). It is similar to the list of
executions on the left, but a red zigzag links events 1 and 3. The structure that MRD generates represents all possible
executions in the same graph, and the zigzag edge, called conflict, indicates a choice that must be made: a single
execution can contain a read of value 0 at
In LB+datas, we are interested in the outcome where both threads read a non-zero value. MRD generates one pre-execution for thread 1 where this is the case, and another similar one for thread 2. Both feature a semantic dependency from the read to the write, and a consequent cycle in ( ∪ ). The outcome is forbidden as a result.
r1 = x . load ( memory_order :: relaxed ); if ( r1 == 42 ) { y . store ( 42 , memory_order :: relaxed ); }
MRD treats LB+ctrl similarly, with a small difference in the generated structure. Recall Thread 1 above.
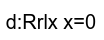
| 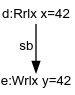
| 
|
| C++ Pre-executions | MRD Event Structure | |
|---|---|---|
In this program, the write is only made if value 42 is read, and that is reflected in the pre-executions of C++ and also the structure generated by MRD. In LB+ctrls, both threads are of this form, and the thin-air outcome is once again forbidden by the presence of the semantic dependency.
r1 = x . load ( memory_order :: relaxed ); if ( r1 == 1 ) { y . store ( 1 , memory_order :: relaxed ); } else { y . store ( 1 , memory_order :: relaxed ); }
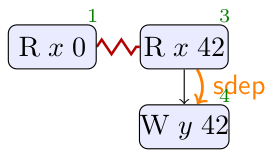
The first thread of LB+false+ctrl, given above, has a false dependency from the load of
|
| 
|
| C++ Pre-executions | MRD Event Structure | |
|---|---|---|
C++ calculates the list of pre-executions above on the left. To allow the optimisation, C++ again omits any dependency ordering, but in this case that turns out to be appropriate.
MRD again combines all of the executions into a single structure, indicating with the red zigzag of conflict where
choices must be made to identify a single execution. There is enough information in this structure to spot that
regardless of the choices made, a write of value 1 to y is always performed. This is precisely what the machinery of MRD
does as it builds the structure, and as a consequence it omits the dependency. We say that the write of y has been lifted above its dependency on the load of
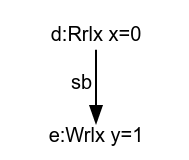
We now discuss the machinery that performs lifting in MRD, using LB as an example. Recall that the relaxed outcome where both threads read 1 must be allowed, otherwise relaxed atomics cannot be implemented efficiently as plain loads and stores on the Power and ARM architectures.
r1 = x . load ( memory_order :: relaxed ); y . store ( 1 , memory_order :: relaxed );
We describe how MRD calculates the executions of the first thread of LB, given above.
|
|
|
|
| C++ Pre-executions | MRD Event Structure | |
|---|---|---|
MRD builds its structures following the program syntax. In contrast to other models, it works from back to front, so for
thread 1 of LB, MRD will build the event corresponding to the store of y and then build the events corresponding to the
load of
To build the structure for the first thread of LB, MRD first constructs a write event corresponding to the store to
y. At this point, before MRD has interpreted the load, we have a structure with a single write. No choices need to be
made to reach the write, so MRD builds a justification reflecting this, linking the empty set to the write. In this
case, we say that the write of
Next MRD interprets the load of
On interpreting the load of
Once MRD has interpreted the whole program, the justification relation is used to construct the relation. In this case is empty.
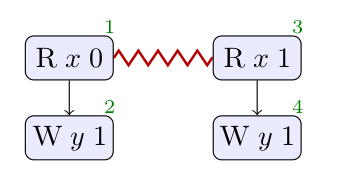
r1 = x . load ( memory_order :: relaxed ); y . store ( r1 , memory_order :: relaxed );
MRD builds its structure for the first thread of LB+datas similarly, but here the stores are dependent on the state of
the registers. MRD has a symbolic representation of the register store that it resolves as it interprets the program. On
interpreting the load of x, the event corresponding to the store of
The conflicting reads are constructed as before, but the construction of justification is different. Now the choice of
read does have a bearing on what write comes next. Reading 0 from
Through these steps, MRD produces the structure above, and forbids the outcome where both threads read 1.
4. MRDer
We have built a tool that takes C-like programs as input and evaluates them under the C++ memory model augmented with MRD (MRDC). The language supports non-atomics, atomics, RMWs, fences, forks and joins. This combination uses the RC11 model, incorporating all known fixes to the original C++ specification. Most litmus tests are evaluated in under a minute on a modestly spec’d computer (16GB of Memory, Intel i5-5250U @ 1.60GHz (2.5GHz turbo)).
The performance of the tool is largely proportional to the size of the program being evaluated. For example, a variant of ISA2 with fences is evaluated in 1.5s, whereas without the fences it is evaluated in 0.8s. We have run the tool on 100 hand-chosen tests, and we believe the performance to be compatible with automated testing.
We will ultimately release the code but for now, in development, please eagerly email us with questions about the tool. We can execute tests for you, or we can work together to get MRDer working in conjunction with your own tools.
The RFUB test, below, was recently discussed in P1217R1.
// Thread 1: r1 = x . load ( memory_order :: relaxed ); y . store ( r1 , memory_order :: relaxed ); // Thread 2: bool assigned_42 ( false); r2 = y . load ( memory_order :: relaxed ); if ( r2 != 42 ) { assigned_42 = true; r2 = 42 ; } x . store ( r2 , memory_order :: relaxed ); assert_not ( assigned_42 );
We used MRDer to evaluate this test, and the outcome in question is allowed by MRDC as desired:
5. Conclusion
MRD is one possible solution to the thin-air problem. Its machinery is orthogonal to the conditions of the existing memory model, and as a consequence, it could be implemented within the standard in a localised and self-contained way. Moreover, all of the refinements made to the current standard would be carried over. MRDer makes it clear that MRD can be evaluated efficiently, and enables us to quickly answer questions about how it behaves.
Refinement of MRD will benefit from:
-
interesting tests or optimisations that should be supported in the memory model, and
-
discussion of the details with members of SG1.
We believe MRDC hits quite a few desirable properties for a revision of the C++ concurrency model:
-
continued support of
ld ; st -
reasoning about programs with RFUB behaviour,
-
implementability at no additional cost on major architectures (ARM, POWER, x86, RISC-V),
-
augmentation of RC11, incorporating all known fixes to C++ concurrency,
-
extension, rather than re-creation, of the existing standard,
-
potential route to redefining
memory_order :: consume -
application to other memory models with an axiomatic representation, e.g. Java, Linux and OpenCL.